 Saltyfish
31 Июля 2025
Saltyfish
31 Июля 2025
На дворе 2025 год: ваш набор инструментов для Python — это не только PyCharm
Экосистема Python становится все больше и больше, постоянно появляются новые инструменты. Чувствуете себя немного растерянно? Без паники.
Эта статья отсеивает всё лишнее. Мы поговорим только о сверхсовременных инструментах, которые по-настоящему меняют правила игры и выведут ваш опыт разработки на новый уровень в 2025 году.
ServBay: Попрощайтесь с утомительными окружениями Python
Скажем честно: настройка окружения Python — это главная головная боль для новичков, где Python 2.x и 3.x легко могут превратиться в хаос. Да что там новички, даже опытные разработчики часто ломают голову, работая с разными версиями Python для разных проектов.
Теперь есть ServBay. Считайте его супер-набором инструментов для разработчиков.
С ним установка Python — дело нескольких кликов. Более того, у вас могут быть установлены одновременно несколько версий, например, Python 3.8, 3.10 и 3.12. Используйте любую, какая вам нужна и когда нужна. Они не будут конфликтовать, а будут мирно сосуществовать.
И вот главная фишка: Вам не нужно вводить ни единой команды.
Больше не нужно возиться с ошибками компиляции pyenv или увязать в настройках окружения miniconda. ServBay позволяет вам сосредоточиться на том, что действительно важно — на написании кода.
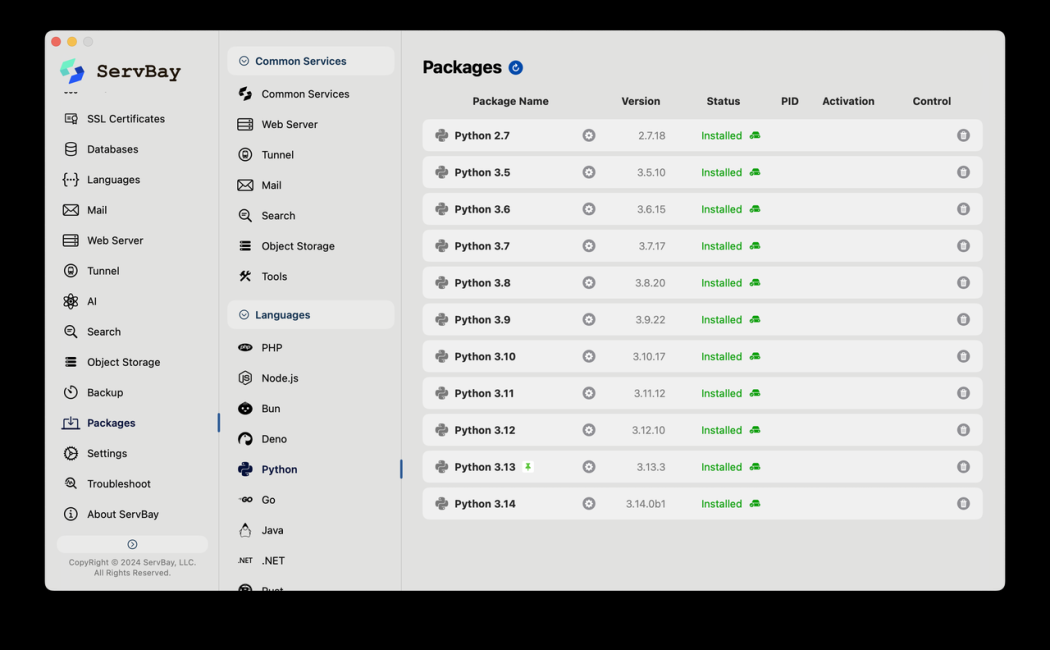
Когда речь идет о настройке окружения, если это занимает больше 5 минут, ServBay — это быстро. Если меньше 5 минут — ServBay это и качественно, и быстро. Кроме того, ServBay предлагает и другие инструменты, необходимые разработчикам, но это я оставлю вам для самостоятельного изучения.
Ruff: Невероятно быстрый линтер
Ваш код постоянно критикуют коллеги за проблемы с форматированием? Ruff приходит на помощь. Он написан на Rust, и прежде чем говорить о других его особенностях, скажем одно: он быстрый.
Насколько быстрый? Настолько, что вы можете настроить форматирование при сохранении, и к тому времени, как вы нажмете Ctrl+S, ваш код уже будет красиво организован.
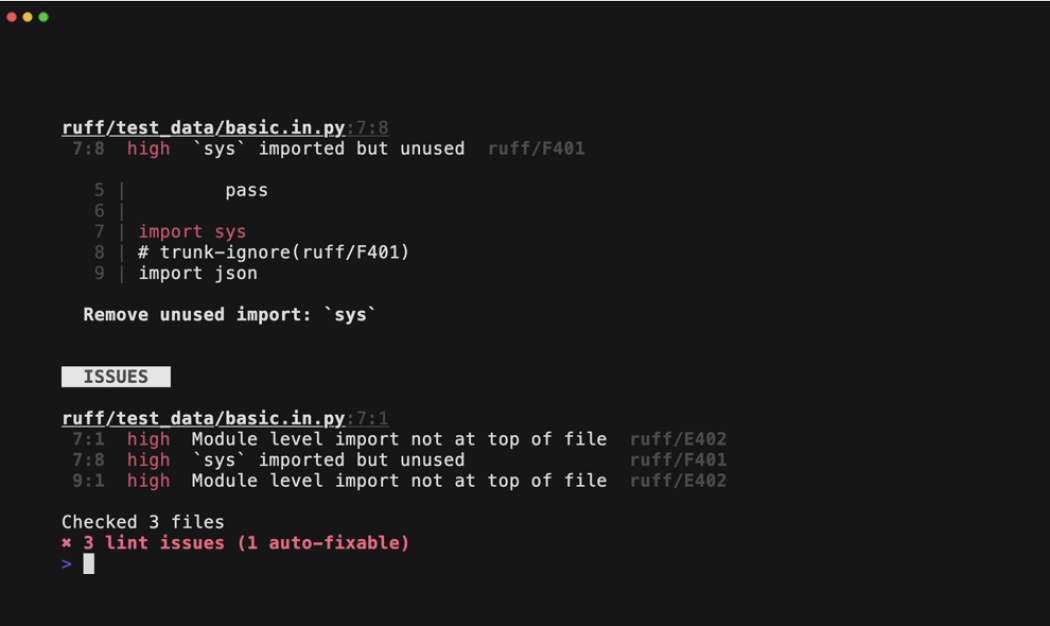
Например, в коде ниже есть три небольшие проблемы: опечатка в имени переменной, импорт не в начале файла и неиспользуемый импорт.
data = datas[0]
import collections
Запустите Ruff, и он немедленно выдаст вам кристально чистый список проблем:
$ ruff check .
ruff.py:1:8: F821 Undefined name `datas`
ruff.py:2:1: E402 Module level import not at top of file
ruff.py:2:8: F401 [*] `collections` imported but unused
Found 3 errors.
[*] 1 potentially fixable with the --fix option.
mypy: Находите проблемы до того, как ваш код упадёт
«Динамические языки — это весело, пока не придётся делать рефакторинг». Жестоко, но правдиво. mypy проводит «проверку здоровья» вашего кода еще до его запуска.
Например, допустим, вы пытаетесь разделить строку на 10, что очевидно неверно.
def process(user: dict[str, str]) -> None:
# mypy поднимет красный флаг здесь!
user['name'] / 10
user: dict[str, str] = {'name': 'alpha'}
process(user)
Даже не запуская код, mypy прямо скажет вам: «Приятель, здесь что-то не так!»
$ mypy --strict mypy_intermediate.py
mypy_fixed.py:2: error: Unsupported operand types for / ("str" and "int")
Found 1 error in 1 file (checked 1 source file)
В больших проектах эта способность находить проблемы на ранней стадии может стать настоящим спасением.
Pydantic: Хватит использовать «голые» словари
Все еще передаете словари (dict) туда-сюда? Кто знает, какие ключи внутри, и какого они типа? Pydantic позволяет вам определять структуры данных так же четко, как вы бы определили обычный класс Python.

Дело не только в четкой структуре; он также автоматически проверяет ваши данные.
import uuid
import pydantic
class User(pydantic.BaseModel):
name: str
id: str | None = None
@pydantic.validator('id')
def validate_id(cls, user_id: str) -> str | None:
if user_id is None: return None
try:
# Проверяем, является ли ID действительным UUID v4
uuid.UUID(user_id, version=4)
return user_id
except ValueError:
# Если нет, возвращаем None
return None
# 'invalid' будет автоматически преобразован в None
users = [ User(name='omega', id='invalid') ]
print(users[0])
Видите? id='invalid' был автоматически проверен и установлен в None. Надежность вашего кода взлетела до небес.
name='omega' id=None
Typer: Создание CLI должно быть таким простым
Хотите добавить интерфейс командной строки к вашему скрипту? Забудьте о шаблонном коде argparse. С Typer вы просто пишете обычную функцию Python и добавляете к ее параметрам подсказки типов.

import typer
app = typer.Typer()
@app.command()
def main(name: str) -> None:
print(f"Hello {name}")
if __name__ == "__main__":
app()
И вот так просто рождается полнофункциональный CLI с собственной справочной документацией (--help). Запустить его так же просто:
$ python main.py "World"
Hello World
Rich: Оживите ваш терминал
Устали от монотонного черно-белого вывода в терминале? Rich может сделать ваш терминал ярким и красочным.

from rich import print
user = {'name': 'omega', 'id': 'invalid'}
# Rich может красиво выводить структуры данных и даже поддерживает эмодзи
print(f"👋 Rich printing\nuser: {user}")
Вывод выглядит так. Разве не намного лучше стандартного print?
👋 Rich printing user: {’name“: „omega“, „id“: „invalid“}
Polars: Демон скорости для табличных данных
Если вы когда-либо обрабатывали умеренно большой набор данных с помощью Pandas, вы знаете муки ожидания. Polars — это новый вариант, который во многих случаях намного быстрее Pandas.
import polars as pl
df = pl.DataFrame({
'date': ['2025-01-01', '2025-01-02', '2025-01-03'],
'sales': [1000, 1200, 950],
'region': ['North', 'South', 'North']
})
# Цепочки операций понятны, а ленивые вычисления повышают производительность
query = (
df.lazy()
.with_columns(pl.col("date").str.to_date())
.group_by("region")
.agg(
pl.col("sales").mean().alias("avg_sales"),
pl.col("sales").count().alias("n_days"),
)
)
print(query.collect())
Результат кристально чист, а вычисления высокооптимизированы и эффективны.
shape: (2, 3)
┌────────┬───────────┬────────┐
│ region ┆ avg_sales ┆ n_days │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞════════╪═══════════╪════════╡
│ North ┆ 975.0 ┆ 2 │
│ South ┆ 1200.0 ┆ 1 │
└────────┴───────────┴────────┘
Pandera: Инспектор качества для ваших данных
80% анализа данных — это их очистка. Pandera действует как инспектор качества. Вы заранее определяете схему данных, и любые данные, не соответствующие ей, немедленно отклоняются.
import pandera as pa
from pandera.polars import DataFrameSchema, Column
schema = DataFrameSchema({
"sales": Column(int, checks=[pa.Check.greater_than(0)]),
"region": Column(str, checks=[pa.Check.isin(["North", "South"])]),
})
# Этот DataFrame содержит отрицательное значение sales и не пройдет проверку
bad_data = pl.DataFrame({"sales": [-1000, 1200], "region": ["North", "South"]})
try:
schema(bad_data)
except pa.errors.SchemaError as err:
print(err) # Pandera скажет вам, что именно не так
Это гарантирует, что в вашу основную логику попадают только чистые данные, избавляя вас от множества проблем в будущем.
DuckDB: Карманная ракета для аналитических SQL-запросов
Не дайте названию вас обмануть, оно не имеет ничего общего с утками. DuckDB — это супер-удобная встраиваемая база данных. Считайте ее SQLite, но созданной специально для анализа данных. Она может запрашивать файлы Parquet и CSV напрямую с невероятной скоростью, используя стандартный синтаксис SQL. Не нужно запускать тяжелый сервер баз данных, чтобы наслаждаться мощью и удобством SQL в ваших Python-скриптах. Это просто находка для быстрого исследования данных и прототипирования.

import duckdb
# (Предполагается, что файлы sales.csv и products.parquet уже созданы)
con = duckdb.connect()
# Прямое объединение двух файлов разных форматов с помощью SQL
result = con.execute("""
SELECT s.date, p.name, s.amount
FROM 'sales.csv' s JOIN 'products.parquet' p ON s.product_id = p.product_id
""").df()
print(result)
Loguru: Логирование без усилий
Встроенный модуль logging в Python мощный, но его настройка может быть немного громоздкой. Loguru все упрощает.
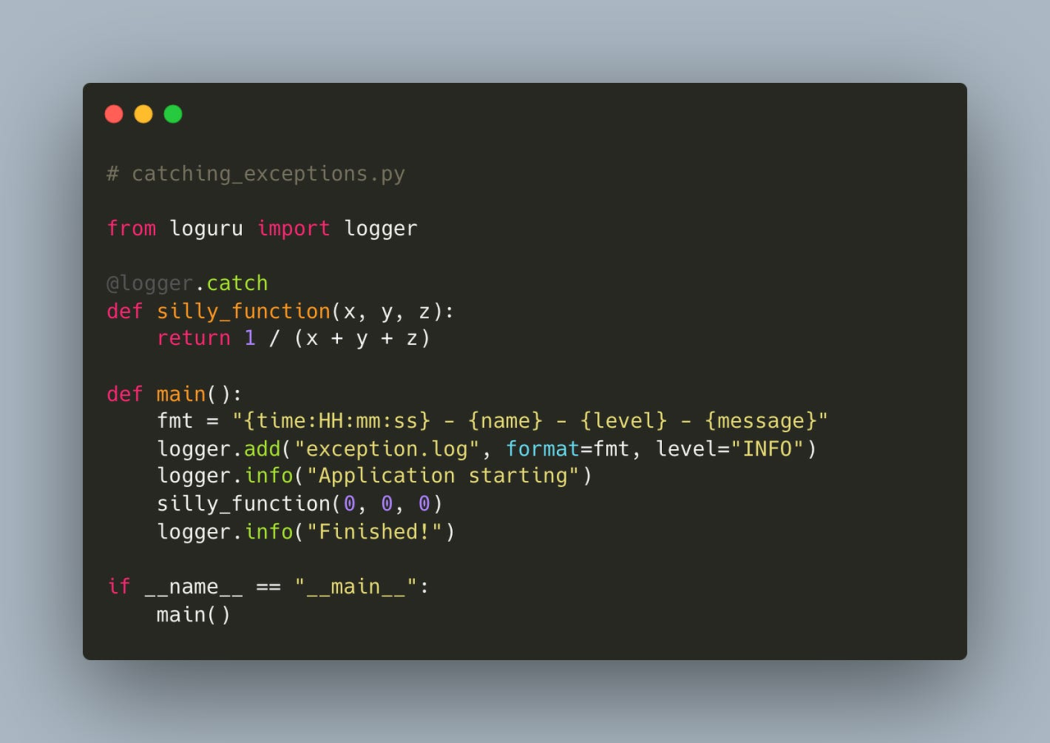
from loguru import logger
# Одной строкой конфигурации можно настроить автоматическую ротацию и сжатие логов
logger.add("file.log", rotation="500 MB")
logger.info("This is an info message")
logger.warning("Warning! Something happened!")
Вывод автоматически включает временную метку, уровень и другую информацию, что делает его невероятно удобным.
2025-01-05 10:30:00.123 | INFO | main:<module>:6 - This is an info message 2025-01-05 10:30:00.124 | WARNING | main:<module>:7 - Warning! Something happened!
Marimo: Интерактивный Python Notebook нового поколения
Jupyter великолепен, но у него есть старые проблемы: нарушьте порядок выполнения ячеек, и состояние может превратиться в полный хаос; файлы .ipynb — это кошмар для систем контроля версий. Marimo пытается решить эти проблемы. Его блокноты — это чистые Python-скрипты, что делает их удобными для Git. К тому же, он «реактивный» — измените переменную, и все зависимые ячейки автоматически обновятся.
Подведем итоги
В 2025 году, если вы хотите поднять вашу разработку на Python на новый уровень, попробуйте этот набор инструментов:
- Управление окружением: Используйте ServBay для установки в один клик.
- Качество кода: Ruff + mypy для скорости и стабильности.
- Определение данных: Pydantic, чтобы перестать использовать «голые», неструктурированные данные.
- Разработка инструментов: Typer для CLI, Rich для красивого вывода.
- Обработка данных: Polars для скорости, Pandera для качества, DuckDB для гибких запросов.
- Повседневные помощники: Loguru для простого логирования, Marimo для нового опыта работы с блокнотами.
Начните использовать их, и вы обнаружите, что писать на Python может быть так приятно.